Apprentissage supervisé
L'apprentissage supervisé est une méthode d'entraînement de modèle d'intelligence artificielle où un modèle est entraîné sur des données étiquetées pour prédire des résultats sur des données nouvelles. Cette approche est très répandue dans les tâches de classification, de régression ou de reconnaissance d'images par exemple.
Illustration
Prenons l'exemple de la classification d'images de véhicules. À partir d'un ensemble d'images préalablement et correctement étiquetées (par exemple, des photos de vélos, motos et trottinettes avec leurs labels respectifs), le modèle apprend à distinguer les caractéristiques propres à chaque catégorie.
Algorithme k-NN
L'algorithme k-NN (k-Nearest Neighbors), ou k-plus proches voisins, attribue une classe à un nouvel élément en analysant ses k voisins les plus proches.
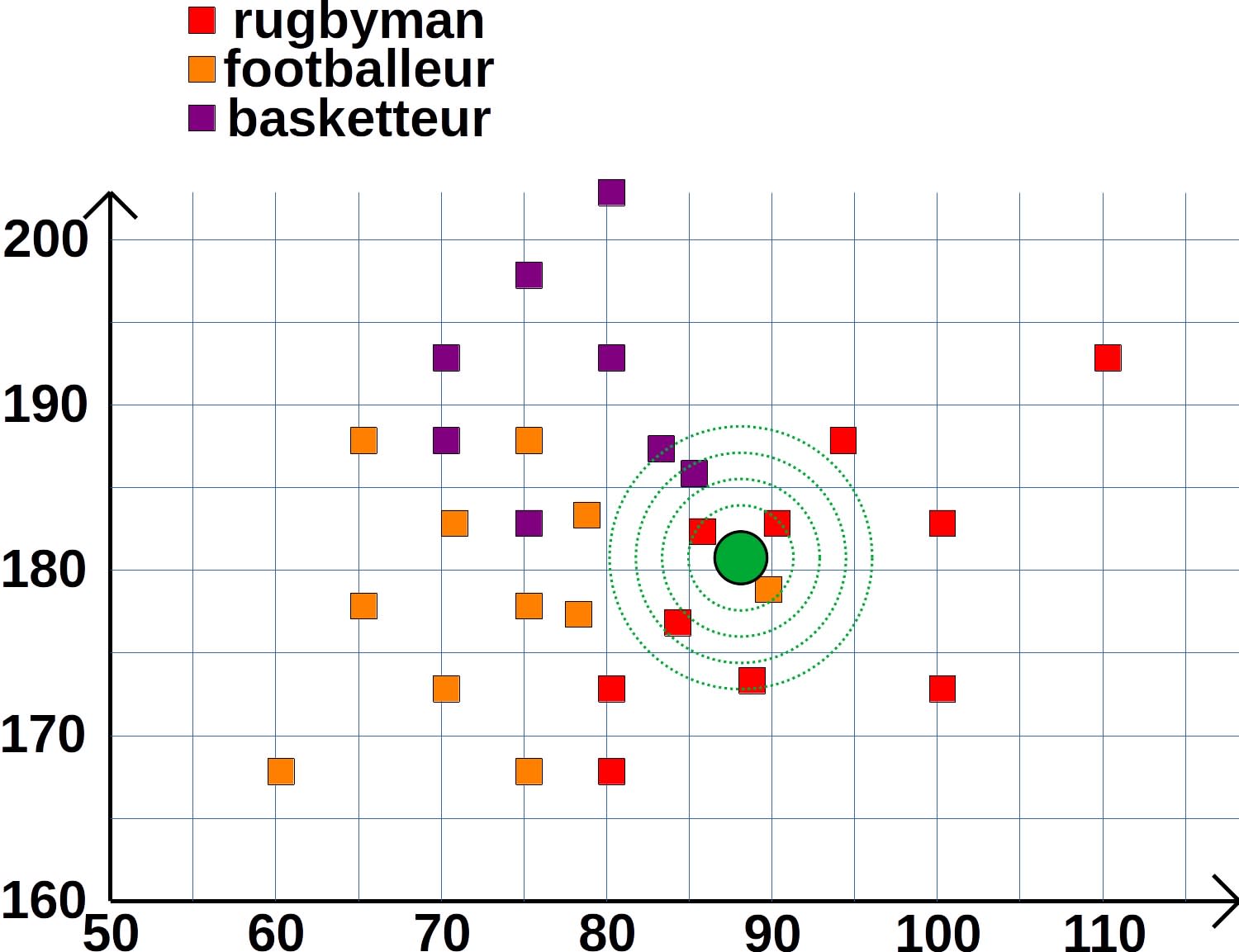
Exemple
Soit une série d'athlètes représentés dans un espace à 2 dimensions, dans lequel deux caractéristiques les décrivent : le poids (abscisse) et la taille (ordonnée). Chaque athlète est étiquetée avec son sport. L'algorithme k-NN, avec pour métrique la distance euclidienne, pourra prévoir le sport d'un nouveau sportif (point vert) à partir du sport de ses 3 plus proches voisins par exemple (ici rugby).
k-d tree
L'utilisation d'arbres k-dimensionnels, ou k-d trees, optimisent considérablement la recherche des k-plus-proches voisins dans l'algorithme k-NN, notamment lorsque les données sont nombreuses ou multidimensionnelles.
Remarque : le k de k-dimensionnels représente le nombre de dimensions de l'espace, il ne doit pas être confondu avec le k dans k-NN.
Dans l'exemple avec les athlètes, le 2-d tree serait un arbre binaire de recherche dont le premier niveau se baserait sur le poids pour ranger les athlètes, le second sur la taille, puis les autres niveaux alterneraient entre taille et poids.
Arbres de décision et ID3
Arbre de décision
Les arbres de décision fonctionnent en posant des questions hiérarchiques sur les données, permettant de les diviser en sous-groupes. Par exemple, pour classer des images de véhicules, une question initiale pourrait être : « Ce véhicule a-t-il deux roues ? ». Si oui, la classification continue avec une question plus spécifique, comme : « Ce véhicule a-t-il un guidon ? ». Chaque réponse mène à une nouvelle branche dans l'arbre.
Algorithme ID3
L'algorithme ID3 (Iterative Dichotomiser 3) construit un arbre de décision en choisissant, à chaque étape, l'attribut qui maximise le gain d'information. Le gain d'information se base sur une mesure appelée entropie, qui reflète le degré de mélange des classes dans un ensemble. Plus un sous-groupe est homogène après la division, plus l'entropie diminue et plus le gain d'information est élevé.
En répétant ce processus de manière récursive, ID3 construit un arbre binaire où chaque nœud correspond à une question ou un test sur un attribut, et chaque feuille représente une classe.
