Apprentissage non supervisé
L'apprentissage non-supervisé est une technique d'intelligence artificielle permettant de découvrir des structures ou classifications cachées dans des données non étiquetées. Contrairement à l'apprentissage supervisé, le modèle n'a pas de réponses préalables mais organise les données selon leurs similitudes.
Illustration
Prenons l'exemple de la classification d'images de véhicules, avec une série d'images représentant des vélos, motos et trottinettes sans indications préalables fournies au modèle. L'algorithme devra découvrir ces groupes en analysant les caractéristiques communes (taille, forme, couleur, etc.).
Classification hiérarchique ascendante
L'algorithme de classification hiérarchique ascendante (CHA) procède par regroupements successifs des données les plus similaires. Au départ, chaque donnée individuelle est considérée comme un groupe distinct. À chaque étape, les deux groupes ou points les plus proches sont fusionnés, ce qui réduit le nombre total de groupes. La similarité est mesurée à l'aide d'une métrique, comme la distance euclidienne ou de Manhattan par exemple.
L'algorithme continue ce processus jusqu'à ce qu'il n'y ait plus qu'un seul groupe englobant toutes les données ou jusqu'à atteindre un critère d'arrêt défini, comme un nombre cible de groupes. Les résultats sont représentés sous la forme d'un dendrogramme : un arbre hiérarchique où chaque nœud correspond à une fusion et chaque branche montre comment les groupes se forment.
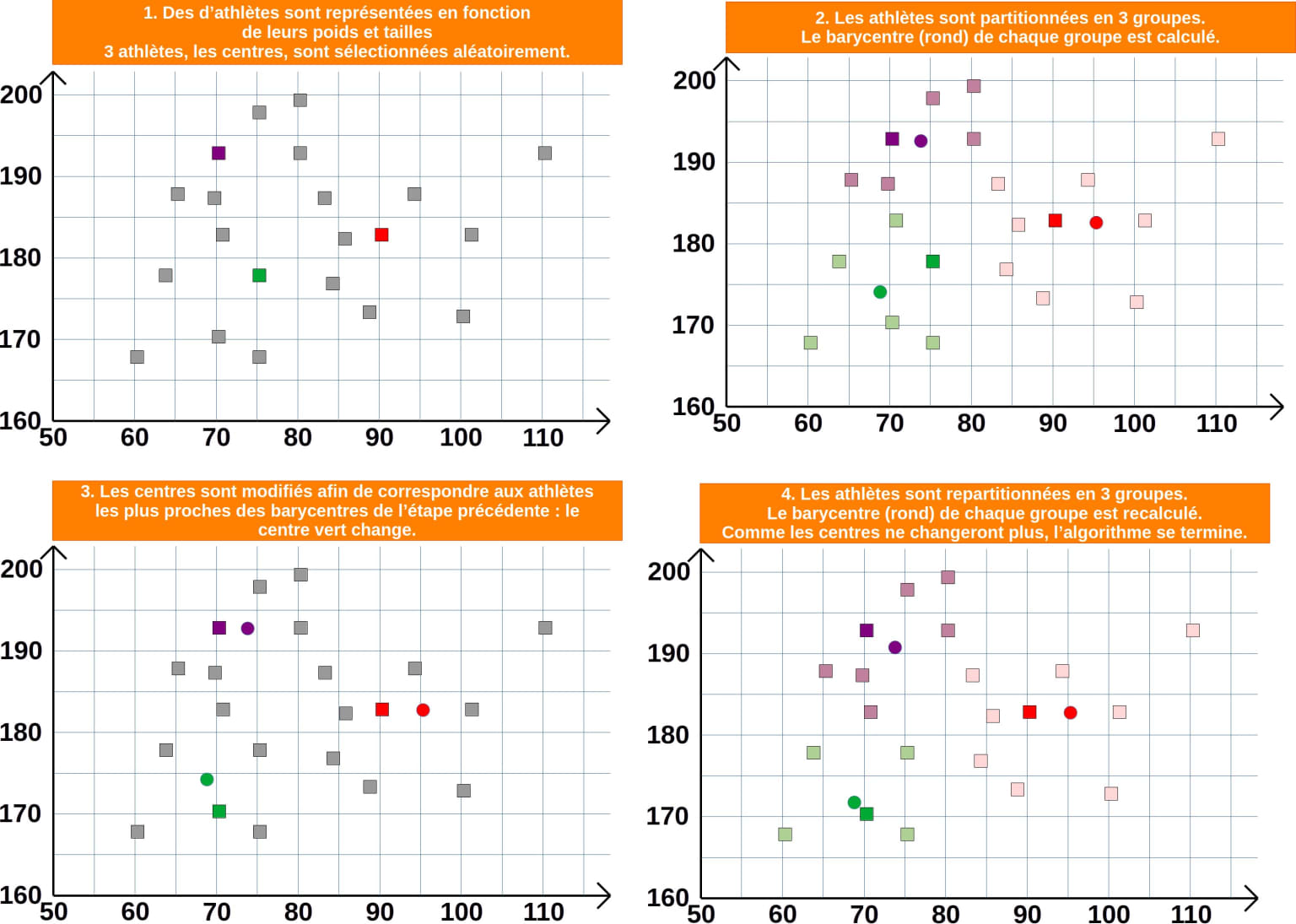
Algorithme des k-moyennes
L'algorithme des k-moyennes partitionne les données en k groupes en minimisant la variance intra-groupe. Il commence par définir k centres initiaux (aléatoires ou basés sur des heuristiques). Chaque point est assigné au centre le plus proche, et les centres sont recalculés comme barycentres des groupes formés. Ce processus est répété jusqu'à convergence, lorsque les centres ne changent plus.
Cet algorithme converge car l'erreur globale (somme des distances aux centres) diminue à chaque itération. Cependant, les résultats peuvent dépendre des conditions initiales.
Remarque : le k de k-moyenne n'a pas de lien avec le k dans k-NN ou dans k-d tree.
Exemple
Soit une série d'athlètes représentés dans un espace à 2 dimensions, dans lequel deux caractéristiques les décrivent : le poids (abscisse) et la taille (ordonnée).
Voici comment l'algorithme des k-moyennes pourrait faire apparaître 3 groupes :