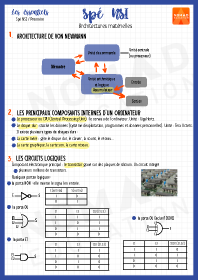
Le format CSV
Définition et caractéristiques
Un fichier CSV est un fichier texte, par opposition aux formats dits « binaires ». Ce format informatique ouvert permet de représenter des données tabulaires sous forme de valeurs séparées par des virgules.
Chaque ligne du texte correspond à une ligne du tableau et les virgules correspondent aux séparations entre les colonnes. Le sigle CSV signifie Comma-Separated Values.
Exemple de fichier CSV
Voici un exemple de fichier CSV :
$$\text{Titre,Réalisateur,Année de sortie}\\ \text{Forest Gump,Robert Zemeckis,1994}\\ \text{Bohemian Rhapsody,Bryan Singer,2018}\\ \text{Le Dictateur,Charles Chaplin,1945}$$
La première ligne est un entête qui donne les noms des colonnes du fichier. Dans cet exemple, le fichier CSV contient une liste de films avec comme informations : le titre, le réalisateur et l'année de sortie du film.
Variantes de séparateurs
Il est possible d'utiliser un autre caractère de séparateur que la virgule. Par exemple, en français, la virgule étant le séparateur des chiffres décimaux, on préfère utiliser comme séparateur le point-virgule ( ;).
Compatibilité et utilisation
Les tableurs, tels que "Calc" (Libre Office) ou Microsoft Excel sont capables de lire les fichiers au format CSV.
Avantages et limites
Le format CSV permet de stocker des données en un minimum d'espace mémoire, de manière simple et facile à lire pour un programme informatique. En revanche, il ne permet pas de produire des structures de données très élaborées, comme d'autres formats (JSON ou XML par exemple).