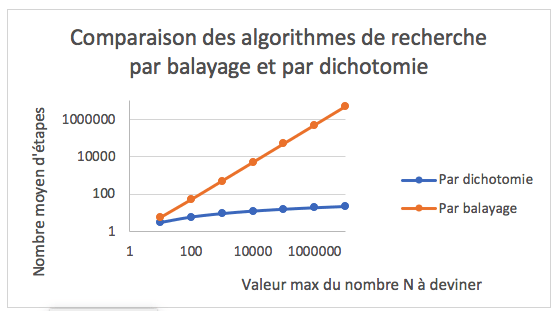
Recherche d'un nombre entier secret par balayage
Voici un programme Python qui permet d'effectuer la recherche d'un nombre entier secret avec la méthode par balayage.
Code du programme
$$\color{black}{\boxed{\scriptstyle{\textit{from random import *}\\ \textit{def ResultatEssai(essai,nombre_secret):}\\ \quad \textit{if essai < nombre_secret:}\\ \qquad\textit{return -1}\\ \quad\textit{elif essai == nombre_secret:}\\ \qquad\textit{return 0}\\ \quad\textit{return 1}\\ \quad\\ \textit{def recherche_pa_balayage(nombre_secret):}\\ \quad\textit{for i in range(1,101):}\\ \qquad\textit{if ResultatEssai(i,nombre_secret) ==0:}\\ \quad \qquad\textit{return i}\\ \quad \qquad\textit{nombre_secret = randint(1,101)}\\ \quad \qquad\textit{print(recherche_par_balayage(nombre_secret))}}}}$$
Fonctionnement de la fonction ResultatEssai
La fonction Python nommée ResultatEssai(essai,nombre_secret) retourne :
- -1 si le nombre essai est strictement inférieur au nombre secret
- 0 si le nombre essai est égal au nombre secret
- 1 si le nombre essai est strictement supérieur au nombre secret
Fonctionnement de la fonction de recherche
La fonction Python recherche_par_balayage(nombre_secret) effectue la recherche d'un nombre secret avec une méthode par balayage et retourne le nombre de tentatives.